C++ How Do You Read a Text File in Rows and Columns
There are a couple of cardinal deportment that y'all will do with Microsoft Excel documents. One of the about basic is the act of reading information from an Excel file. You will be learning how to get data from your Excel spreadsheets. Editor'due south notation: This article is based on a chapter from the book: Automating Excel with Python. You can gild a re-create on Gumroad or Kickstarter. Before you dive into automating Excel with Python, you should empathise some of the common terminologies: Now that you have some basic understanding of the vocabulary, you lot can move on. In this chapter, you volition larn how to do the following tasks: You tin can get started by learning how to open up a workbook in the adjacent department! The get-go detail that you need is a Microsoft Excel file. Yous can use the file that is in this GitHub code repository. There is a file in the affiliate two binder chosen Information technology has two sheets in it. Hither is a screenshot of the beginning canvas: For completeness, hither is a screenshot of the second sheet: Note: The information in these sheets are inaccurate, merely they help learn how to employ OpenPyXL. Now you lot're prepare to outset coding! Open up up your favorite Python editor and create a new file named The beginning step in this code is to import You lot can get a listing of the worksheets in the Excel file by accessing the Side by side, yous grab the currently active sheet. If your workbook only has one worksheet, so that sheet volition be the agile one. If your workbook has multiple worksheets, every bit this i does, then the last worksheet will exist the active one. The concluding two lines of your function print out the What if yous want to select a specific worksheet to work on, though? To learn how to accomplish that, create a new file and name it And so enter the following lawmaking: Your function, So you print out the sheet's title to verify that y'all accept the right canvass. Y'all likewise call something new: Now you are set up to movement on and acquire how to read information from the cells themselves. In that location are a lot of different ways to read cells using OpenPyXL. To start things off, yous will acquire how to read the contents of specific cells. Create a new file in your Python editor and name it In this example, there are 3 hard-coded cells: A2, A3 and B3. You can access their values past using dictionary-like access: You tin can see both of these methods demonstrated in your code above. When yous run this code, you lot should see the following output: This output shows how you tin easily excerpt specific cell values from Excel using Python. Now you're ready to learn how you can read the information from a specific row of cells! In about cases, you will want to read more a unmarried cell in a worksheet at a time. OpenPyXL provides a mode to go an entire row at once, too. Go ahead and create a new file. You can name it In this example, you pass in the row number two. You can iterate over the values in the row like this: That makes grabbing the values from a row pretty straightforward. When yous run this code, you'll become the following output: Those concluding two values are both None. If you don't desire to get values that are None, yous should add some extra processing to check if the value is None before printing it out. Yous can try to figure that out yourself equally an practise. Yous are now ready to acquire how to go cells from a specific column! Reading the data from a specific column is also a frequent use example that yous should know how to accomplish. For example, y'all might have a column that contains just totals, and you need to extract only that specific column. To see how you lot tin do that, create a new file and proper name it This code is very similar to the code in the previous section. The deviation here is that y'all are replacing In this example, you prepare the column to "A". When you run this code, you volition get the following output: Once again, some columns have no data (i.due east., "None"). You lot can edit this code to ignore empty cells and but process cells that have contents. Now permit's discover how to iterate over multiple columns or rows! There are two methods that OpenPyXL'due south worksheet objects give yous for iterating over rows and columns. These are the two methods: These methods are documented fairly well in OpenPyXL's documentation. Both methods take the following parameters: You employ the min and max rows and column parameters to tell OpenPyXL which rows and columns to iterate over. You can take OpenPyXL render the data from the cells past setting It'due south e'er practiced to meet how this works with bodily code. With that in heed, create a new file named Here you load up the workbook as you have in the previous examples. You get the canvas name that you want to extract data from and and so use Then you also set the columns to be i (minimum) to 3 (maximum). Finally, you set When you run this code, y'all will get the following output: Your program will print out the commencement three columns of the commencement iii rows in your Excel spreadsheet. Your program prints the rows as tuples with three items in them. You lot are using At present you're ready to learn how to read cells in a specific range. Excel lets you lot specify a range of cells using the following format: (col)(row):(col)(row). In other words, you can say that y'all desire to start in column A, row 1, using A1. If you wanted to specify a range, you would employ something like this: A1:B6. That tells Excel that you are selecting the cells starting at A1 and going to B6. Go ahead and create a new file named Hither you pass in your You bank check to see if the cell that you are extracting is a When you lot run this lawmaking, you should see the following output: That worked quite well. You should take a moment and try out a few other range variations to see how it changes the output. Annotation: while the epitome of "Canvas 1 - Books" looks similar cell A1 is distinct from the merged cell B1-G1, A1 is really part of that merged cell. The concluding code example that you'll create will read all the data in your Excel document! Microsoft Excel isn't as uncomplicated to read as a CSV file, or a regular text file. That is considering Excel needs to shop each cell's data, which includes its location, formatting, and value, and that value could exist a number, a date, an image, a link, etc. Consequently, reading an Excel file is a lot more than work! openpyxl does all that hard work for us, though. The natural style to iterate through an Excel file is to read the sheets from left to right, and within each canvass, you would read it row by row, from top to bottom. That is what yous will learn how to do in this section. Y'all volition take what you have learned in the previous sections and apply information technology hither. Create a new file and name it Hither y'all load upwards the workbook as before, but this time you loop over the Once again, y'all skip You can simplify this lawmaking a bit past using In this code, you in one case over again loop over the sheet names in the Excel certificate. However, rather than looping over the rows and columns, you lot utilize When y'all run this code, you volition encounter it print out the proper name of each sheet, then all the information in that sheet, row-by-row. Requite it a try on your own Excel worksheets and see what this code can do! OpenPyXL lets you lot read an Excel Worksheet and its data in many different ways. You tin extract values from your spreadsheets speedily with a minimal amount of code. In this chapter, you learned how to exercise the post-obit: Now you are ready to acquire how to create an Excel spreadsheet using OpenPyXL. That is the subject of the next article in this series!
Open a Spreadsheet
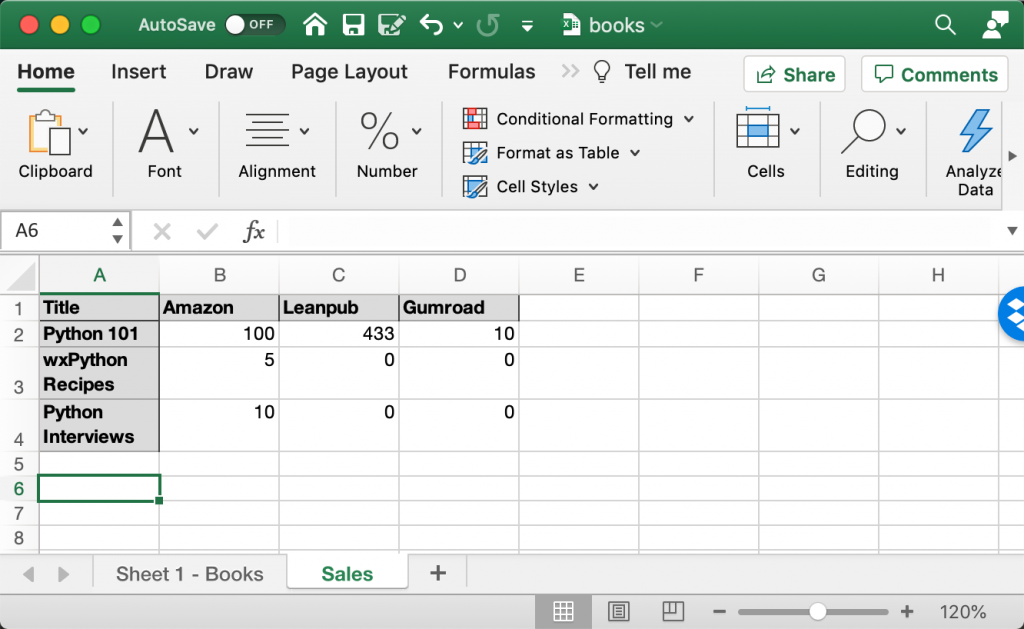
books.xlsx that y'all will use here.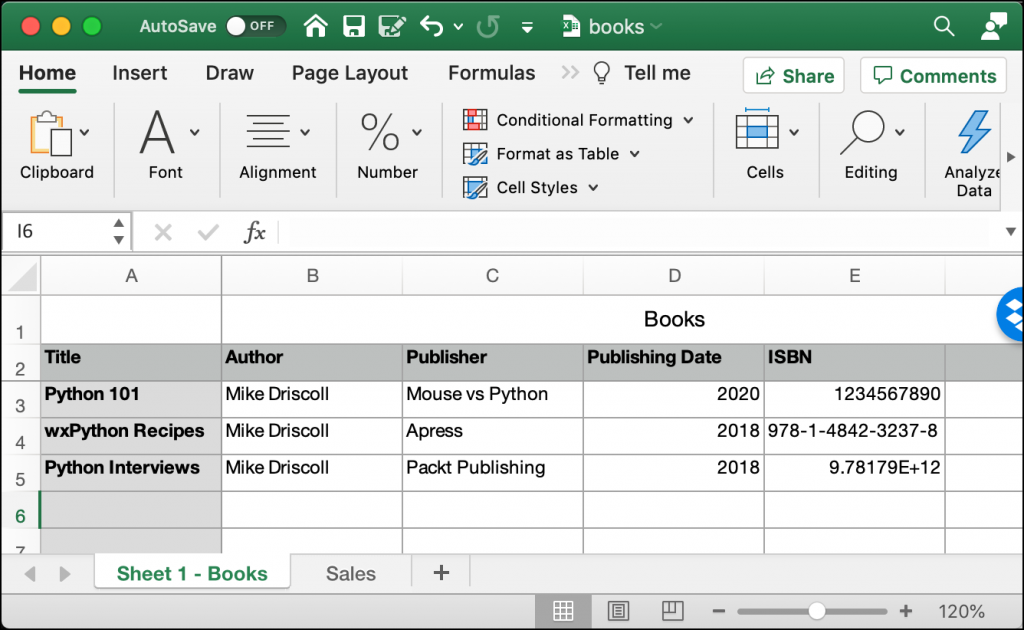
open_workbook.py. Then add the following code to your file:# open_workbook.py from openpyxl import load_workbook def open_workbook(path): workbook = load_workbook(filename=path) print(f"Worksheet names: {workbook.sheetnames}") sheet = workbook.agile print(sheet) print(f"The title of the Worksheet is: {sheet.championship}") if __name__ == "__main__": open_workbook("books.xlsx") load_workbook() from the openpyxl package. The load_workbook() office will load up your Excel file and render it equally a Python object. You can then interact with that Python object like you lot would any other object in Python.sheetnames attribute. This list contains the titles of the worksheets from left to right in your Excel file. Your code will impress out this list.Worksheet object and the title of the active worksheet.read_specific_sheet.py.# read_specific_sheet.py from openpyxl import load_workbook def open_workbook(path, sheet_name): workbook = load_workbook(filename=path) if sheet_name in workbook.sheetnames: sheet = workbook[sheet_name] print(f"The title of the Worksheet is: {canvass.title}") print(f"Cells that contain data: {canvass.calculate_dimension()}") if __name__ == "__main__": open_workbook("books.xlsx", sheet_name="Sales") open_workbook() at present accepts a sheet_name. sheet_name is a string that matches the title of the worksheet that you lot want to read. You check to encounter if the sheet_name is in the workbook.sheetnames in your lawmaking. If it is, you select that sail by accessing it using workbook[sheet_name].calculate_dimension(). That method returns the cells that contain data in the worksheet. In this case, it will print out that "A1:D4" has data in them.Read Specific Cells
reading_specific_cells.py. Then enter the following code:# reading_specific_cells.py from openpyxl import load_workbook def get_cell_info(path): workbook = load_workbook(filename=path) canvass = workbook.active print(sheet) print(f'The title of the Worksheet is: {sheet.title}') print(f'The value of A2 is {sheet["A2"].value}') print(f'The value of A3 is {sheet["A3"].value}') cell = sheet['B3'] print(f'The variable "jail cell" is {cell.value}') if __name__ == '__main__': get_cell_info('books.xlsx') canvas["A2"].value. Alternatively, you can assign sheet["A2"] to a variable and then practice something like cell.value to get the cell's value.<Worksheet "Sales"> The title of the Worksheet is: Sales The value of A2 is 'Python 101' The value of A3 is 'wxPython Recipes' The variable "cell" is 5
Read Cells From Specific Row
reading_row_cells.py. And then add the following code to your program:# reading_row_cells.py from openpyxl import load_workbook def iterating_row(path, sheet_name, row): workbook = load_workbook(filename=path) if sheet_name not in workbook.sheetnames: print(f"'{sheet_name}' not institute. Quitting.") return canvass = workbook[sheet_name] for jail cell in sheet[row]: impress(f"{jail cell.column_letter}{jail cell.row} = {cell.value}") if __name__ == "__main__": iterating_row("books.xlsx", sheet_name="Sheet 1 - Books", row=two) for cell in canvass[row]: ...
A2 = Title B2 = Author C2 = Publisher D2 = Publishing Date E2 = ISBN F2 = None G2 = None
Read Cells From Specific Cavalcade
reading_column_cells.py. Then enter this code:# reading_column_cells.py from openpyxl import load_workbook def iterating_column(path, sheet_name, col): workbook = load_workbook(filename=path) if sheet_name not in workbook.sheetnames: print(f"'{sheet_name}' not found. Quitting.") return sheet = workbook[sheet_name] for jail cell in canvas[col]: print(f"{cell.column_letter}{jail cell.row} = {cell.value}") if __name__ == "__main__": iterating_column("books.xlsx", sheet_name="Sheet 1 - Books", col="A") sheet[row] with sheet[col] and iterating on that instead.A1 = Books A2 = Championship A3 = Python 101 A4 = wxPython Recipes A5 = Python Interviews A6 = None A7 = None A8 = None A9 = None A10 = None A11 = None A12 = None A13 = None A14 = None A15 = None A16 = None A17 = None A18 = None A19 = None A20 = None A21 = None A22 = None A23 = None
Read Cells from Multiple Rows or Columns
iter_rows() iter_cols()
min_col (int) – smallest column index (1-based index)min_row (int) – smallest row index (1-based index)max_col (int) – largest column index (one-based index)max_row (int) – largest row index (1-based index)values_only (bool) – whether just cell values should be returnedvalues_only to True. If you lot set it to False, iter_rows() and iter_cols() will return cell objects instead.iterating_over_cells_in_rows.py and add together this code to it:# iterating_over_cells_in_rows.py from openpyxl import load_workbook def iterating_over_values(path, sheet_name): workbook = load_workbook(filename=path) if sheet_name not in workbook.sheetnames: impress(f"'{sheet_name}' not found. Quitting.") render sheet = workbook[sheet_name] for value in sheet.iter_rows( min_row=1, max_row=three, min_col=1, max_col=3, values_only=Truthful): print(value) if __name__ == "__main__": iterating_over_values("books.xlsx", sheet_name="Sail 1 - Books") iter_rows() to get the rows of information. In this case, you set up the minimum row to 1 and the maximum row to iii. That ways that you will take hold of the first three rows in the Excel sheet you have specified.values_only to True.
('Books', None, None) ('Title', 'Author', 'Publisher') ('Python 101', 'Mike Driscoll', 'Mouse vs Python') iter_rows() as a quick manner to iterate over rows and columns in an Excel spreadsheet using Python.Read Cells from a Range
read_cells_from_range.py. Then add this code to it:# read_cells_from_range.py import openpyxl from openpyxl import load_workbook def iterating_over_values(path, sheet_name, cell_range): workbook = load_workbook(filename=path) if sheet_name not in workbook.sheetnames: print(f"'{sheet_name}' non found. Quitting.") return sheet = workbook[sheet_name] for column in sheet[cell_range]: for jail cell in cavalcade: if isinstance(cell, openpyxl.cell.cell.MergedCell): # Skip this cell keep impress(f"{jail cell.column_letter}{prison cell.row} = {prison cell.value}") if __name__ == "__main__": iterating_over_values("books.xlsx", sheet_name="Sheet 1 - Books", cell_range="A1:B6") cell_range and iterate over that range using the post-obit nested for loop:for cavalcade in sheet[cell_range]: for cell in column:
MergedCell. If it is, you skip it. Otherwise, you print out the cell proper noun and its value.A1 = Books A2 = Title B2 = Author A3 = Python 101 B3 = Mike Driscoll A4 = wxPython Recipes B4 = Mike Driscoll A5 = Python Interviews B5 = Mike Driscoll A6 = None B6 = None
Read All Cells in All Sheets
read_all_data.py. And then enter the following lawmaking:# read_all_data.py import openpyxl from openpyxl import load_workbook def read_all_data(path): workbook = load_workbook(filename=path) for sheet_name in workbook.sheetnames: sheet = workbook[sheet_name] impress(f"Title = {canvass.title}") for row in sheet.rows: for cell in row: if isinstance(cell, openpyxl.cell.prison cell.MergedCell): # Skip this cell proceed print(f"{jail cell.column_letter}{cell.row} = {jail cell.value}") if __name__ == "__main__": read_all_data("books.xlsx") sheetnames. You print out each sheet name as you lot select it. You use a nested for loop to loop over the rows and cells to extract the data from your spreadsheet.MergedCells because their value is None -- the bodily value is in the normal jail cell that the MergedCell is merged with. If you run this code, you will see that information technology prints out all the data from the ii worksheets.iter_rows(). Open a new file and name it read_all_data_values.py. Then enter the following:# read_all_data_values.py import openpyxl from openpyxl import load_workbook def read_all_data(path): workbook = load_workbook(filename=path) for sheet_name in workbook.sheetnames: sheet = workbook[sheet_name] print(f"Title = {sheet.title}") for value in sheet.iter_rows(values_only=True): print(value) if __name__ == "__main__": read_all_data("books.xlsx") iter_rows() to loop over only the rows. You prepare values_only to True which volition return a tuple of values for each row. You also practice non set the minimum and maximum rows or columns for iter_rows() because you desire to become all the data.Wrapping Upwards
smiththerecomed1949.blogspot.com
Source: https://www.blog.pythonlibrary.org/2021/07/20/reading-spreadsheets-with-openpyxl-and-python/
0 Response to "C++ How Do You Read a Text File in Rows and Columns"
Post a Comment